许多现有数据系统中都采用这种数据处理方式:你发送请求指令,一段时间后(我们期望)系统会给出一个结果。
三种不同类型的系统:
服务(在线系统)
服务等待客户的请求或指令到达。每收到一个,服务会试图尽快处理它,并发回一个响应。响应时间通常是服务性能的主要衡量指标,可用性通常非常重要(如果客户端无法访问服务,用户可能会收到错误消息)。
批处理系统(离线系统)
一个批处理系统有大量的输入数据,跑一个作业(job)来处理它,并生成一些输出数据,这往往需要一段时间(从几分钟到几天),所以通常不会有用户等待作业完成。相反,批量作业通常会定期运行(例如,每天一次)。批处理作业的主要性能衡量标准通常是吞吐量(处理特定大小的输入所需的时间)。
流处理系统(准实时系统)
流处理介于在线和离线(批处理)之间,所以有时候被称为准实时(near-real-time)或准在线(nearline)处理。像批处理系统一样,流处理消费输入并产生输出(并不需要响应请求)。但是,流式作业在事件发生后不久就会对事件进行操作,而批处理作业则需等待固定的一组输入数据。这种差异使流处理系统比起批处理系统具有更低的延迟。
UNIX设计哲学
- 每个程序做好一件事。如果要做新的工作,则建立一个全新的程序,而不是通过增加新 “特征” 使旧程序变得更加复杂。
- 期待每个程序的输出成为另一个尚未确定的程序的输入。不要将输出与无关信息混淆在一起。避免使用严格的表格状或二进制输入格式。不要使用交互式输入。
- 尽早尝试设计和构建软件,甚至是操作系统,最好在几周内完成。需要扔掉那些笨拙的部分时不要犹豫,并立即进行重建。
- 优先使用工具来减轻编程任务,即使不得不额外花费时间去构建工具,并且预期在使用完成后将其中的一些工具扔掉。
MapReduce与分布式文件系统
类似UNIX工具,MapReduce需要一个或多个输入,并产生一个或多个输出。在Hadoop的MapReduce实现中,该文件系统称为HDFS,一个Google文件系统的开源实现版本。
HDFS包含一个在每台机器上运行的守护进程,并会开放一个网络服务以允许其他节点访问存储在该机器上的文件。名为NameNode的中央服务器会跟踪哪个文件块存储在那台机器上。考虑到容错,文件块会被复制到多台机器上。
MapReduce作业执行
- 首先读入一组文件,将其分解成记录(records)。
- 调用mapper函数从每个输入记录中提取一个键值对。
- 按关键字将所有的键值对排序。
- 调用reducer函数遍历排序后的所有键值对。如果一个键出现多次,排序会使它们在列表相邻,所以会很容易组合这些值,不用在内存保留很多状态。
mapper
每个输入记录都会调用一次mapper,其任务是从输入记录中提取关键字和值。对每个输入记录,它可以生成任意数量的键值对。
reducer
MapReduce框架使用由mapper生成的键值对,收集属于同一个关键字的所有值,并使用迭代器调用reducer以使用该值的集合。Reducer可以输出记录(算出来的结果)。
MapReduce的分布式执行
MapReduce可以跨多台机器进行分布式并行计算,而且不用编写代码来指示如何并行化。在分布式计算中可以使用标准的UNIX工具作为mapper和reducer,但更长见的是编写代码,比如Hadoop的mapper和reducer都是实现特定接口的Java类。
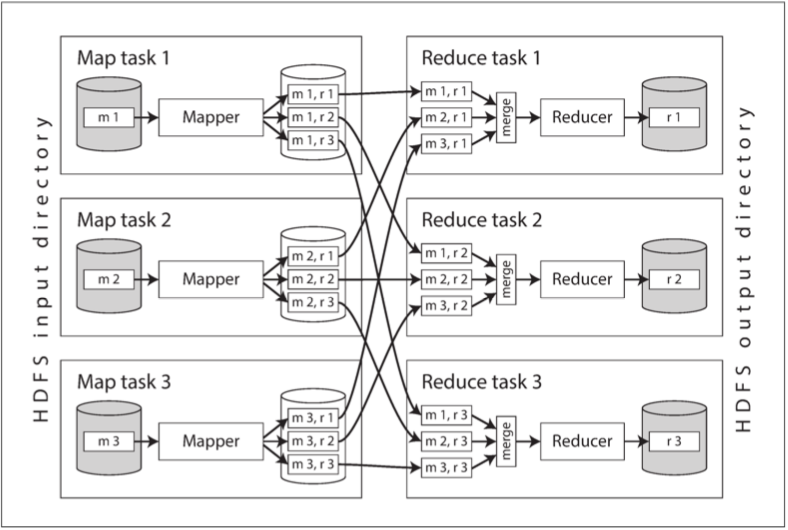
上图是MapReduce作业中的数据流,并行化基于分区实现:作业的输入通常是HDFS中的一个目录,且输入目录中的每个文件或文件块都被视为一个单独的分区,可以由一个单独的map任务来处理。
一个输入文件通常比较大(几百M),只要有足够的空闲内存和CPU资源,MapReduce调度器会尝试在输入文件副本的某台机器运行mapper任务,这个原则被称为计算就近数据:它避免了输入文件通过网络复制,减少网络负载,提高了访问局部性。
由于map任务运行的应用程序代码在分配运行任务的节点并不存在,所以MapReduce框架首先要复制代码到该节点。Reduce任务中的计算也被分割成块,Map任务的数量由输入文件块的数量决定,而reduce任务的数量则是由作业的作者配置的。为了确保具有相同关键字的所有键值对都在相同的reducer任务中处理,框架使用关键字的hash值来确定哪个reduce任务接受特定的键值对。
键值对必须排序,如果数据集太大,可能也无法在单机进行常规的排序算法。事实上,排序是分阶段进行的。首先,每个map任务根据关键字hash值,按照reducer对输出进行分区。每个分区都被写入mapper程序的本地磁盘上的已排序文件。
当mapper完成读取输入文件并写入经过排序后的输出文件,MapReduce调度器就会通知reducer开始从mapper中获取输出文件。reducer与每个mapper相连,并按照其分区从mapper中下载排序后的键值对文件。按照reducer分区,排序,和将数据分区从mapper复制到reducer,这样一个过程称为shuffle。
reduce任务从mapper获取文件并将它们合并在一起,同时保持数据的顺序。
reducer通过关键字和迭代器为参数来调用,迭代器扫描所有具有相同关键字的记录,并用任意逻辑处理这些记录,然后生成任意数量的输出记录。这些输出记录被写入分布式文件系统中的文件。(通常是在跑Reducer的机器本地磁盘上留一份,并在其他机器上留几份副本)。
MapReduce工作流
单个MapReduce作业可以解决的问题范围有限。类似的,UNIX工具,单个工具只能完成部分操作。
因此,将MapReduce作业链接到工作流是很普遍的,这样,一个作业的输出会称为下一个作业的输入。Hadoop MapReduce框架对工作流并没有任何特殊的支持,所以链接方式是通过目录名隐式完成的:第一个作业必须配置为将其输出写入HDFS的指定目录,而第二个作业必须配置为读取相同的目录名作为输入。而MapReduce框架角度来看,它们是两个独立的作业。
所以,链接方式的MapReduce不像UNIX命令流水线(直接将进程的输出作为输入传给下一个进程,只需要很小的内存缓冲区),而是更像一系列命令,其中每个命令的输出被写入临时文件,下个命令从临时文件读取。
只有当作业成功完成时,批处理作业的输出才会被视为有效。因此,作业只有当前面的作业成功完成时才开始。

