把Lambda付诸实践:环绕执行模式
资源处理时常见的一个模式是打开一个资源,做一些处理,然后关闭资源,这个设置和清理阶段类似,并且会围绕着执行处理的业务逻辑。这就是环绕执行模式。
1)第一步,当需要更改逻辑代码是,需要重写代码,所以想到行为参数化
1 | public static String processFile() throws IOException { |
2)第二步,使用函数式接口来传递一个行为
1 |
|
3)第三步,执一个行为,任何BufferReader -> String的Lambda表达式都可以作为参数传入。只要符合peocess方法的签名即可。
1 | public static String processFiles(BufferReaderProcessFile bufferReaderProcessFile)throws IOException { |
4)第四步,传递Lambda
1 | String string = processFiles((BufferedReader bs) -> bs.readLine()); |

使用函数式接口
函数式接口很有用,因为抽象方法的签名可以描述Lambda表达式的签名。函数式接口的抽象方法的签名称为函数描述符。所以为了应用不同的Lambda表达式,需要一套能够描述常见函数描述符的函数式接口。
Java 8的库设计师在java.util.function包中引入了几个新的函数式接口。
几个常用的函数式接口:
Predicate
java.util.function.Predicate<T>接口定义了一个名叫test的抽象方法,它接受泛型T对象,并返回一个boolean。这恰恰和你先前创建的一样,现在就可以直接使用了。在需要表示一个涉及类型T的布尔表达式时,就可以使用这个接口。
1 |
|
Consumer
java.util.function.Consumer<T>定义了一个名叫accept的抽象方法,它接受泛型T的对象,没有返回(void)。如果需要访问类型T的对象,并对其执行某些操作,就可以使用这个接口。比如,可以用它来创建一个forEach方法,接受一个Integers的列表,并对其中每个元素执行操作。
1 |
|
Function
java.util.function.Function<T, R>接口定义了一个叫作apply的方法,它接受一个泛型T的对象,并返回一个泛型R的对象。如果需要定义一个Lambda,将输入对象的信息映射到输出,就可以使用这个接口(比如提取苹果的重量,或把字符串映射为它的长度)。
1 |
|
常用函数式接口


一些使用案例

异常,Lambda,还有函数式接口:
任何的函数式接口都不能抛出受检异常(check exception),如果你需要lambda 表达式抛出异常,有两种方法:
定义一个自己的函数式接口,并申明受检异常,或者把Lambda包在一个try/catch块中。
类型推断、类型检查及限制
使用局部变量
Lambda表达式也允许使用自由变量(不是参数,而是在外层作用域中定义的变量),就像匿名类一样。 它们被称作捕获Lambda。例如,下面的Lambda捕获了portNumber变量:
1 | int portNumber = 1337; |
尽管如此,还有一点点小麻烦:关于能对这些变量做什么有一些限制。Lambda可以没有限制地捕获(也就是在其主体中引用)实例变量和静态变量。但局部变量必须显式声明为final,或事实上是final。换句话说,Lambda表达式只能捕获指派给它们的局部变量一次。(注:捕获实例变量可以被看作捕获最终局部变量this。) 例如,下面的代码无法编译,因为portNumber变量被赋值两次:
1 | int portNumber = 1337; |
对局部变量的限制
你可能会问自己,为什么局部变量有这些限制。第一,实例变量和局部变量背后的实现有一个关键不同。实例变量都存储在堆中,而局部变量则保存在栈上。如果Lambda可以直接访问局部变量,而且Lambda是在一个线程中使用的,则使用Lambda的线程,可能会在分配该变量的线程将这个变量收回之后,去访问该变量。因此,Java在访问自由局部变量时,实际上是在访问它的副本,而不是访问原始变量。如果局部变量仅仅赋值一次那就没有什么区别了——因此就有了这个限制。
在JDK8中如果我们在匿名内部类中需要访问局部变量,那么这个局部变量不需要用final修饰符修饰。看似是一种编译机制的改变,实际上就是一个语法糖(底层还是帮你加了final)。但通过反编译没有看到底层为我们加上final,但我们无法改变这个局部变量的引用值,如果改变就会编译报错。
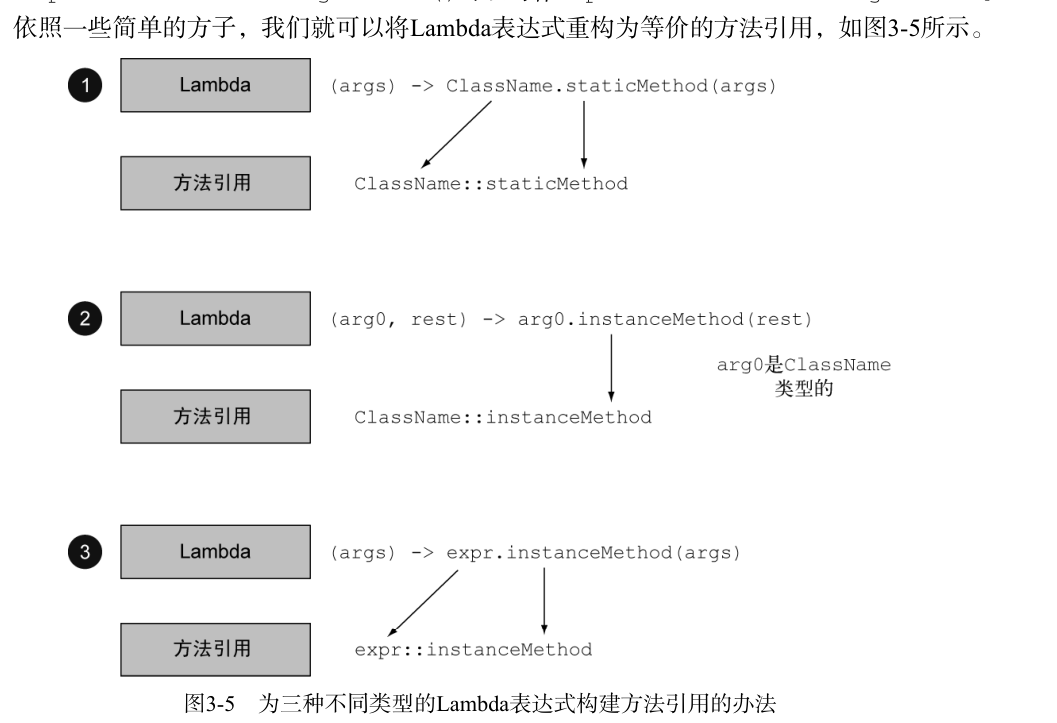
方法引用
需要使用方法引用时,目标引用放在分隔符::前,方法的名称放在后面。

如何构建方法引用
方法引用主要有三类。
(1) 指向静态方法的方法引用(例如Integer的parseInt方法,写作Integer::parseInt)。
(2) 指 向 任 意 类 型 实 例 方 法 的 方 法 引 用 ( 例 如 String 的 length 方 法 , 写 作String::length)。
(3) 指向现有对象的实例方法的方法引用(假设你有一个局部变量expensiveTransaction用于存放Transaction类型的对象,它支持实例方法getValue,那么你就可以写expensiveTransaction::getValue)。
复合 Lambda 表达式的有用方法
比较器复合
使用静态方法Comparator.comparing,根据提取用于比较的键值的Function来返回一个Comparator
1 | Comparator<Apple> c = Comparator.comparing(Apple::getWeight); |
- 逆序
接口有一个默认方法reversed可以使给定的比较器逆序。因此仍然用开始的那个比较器,只要修改一下前一个例子就可以对苹果按重量递减排序:
1 | inventory.sort(comparing(Apple::getWeight).reversed()); |
比较器链
如果发现有两个苹果一样重怎么办?哪个苹果应该排在前面呢?你可能需要再提供一个Comparator来进一步定义这个比较。thenComparing方法就是做这个用的。它接受一个函数作为参数(就像comparing方法一样),如果两个对象用第一个Comparator比较之后是一样的,就提供第二个Comparator。你又可以优雅地解决这个问题了:1
2
3inventory.sort(comparing(Apple::getWeight)
.reversed()
.thenComparing(Apple::getCountry));
谓词复合
谓词接口包括三个方法:negate、and和or,可以重用已有的Predicate来创建更复杂的谓词。
表达要么是重(150克以上)的苹果,要么是绿苹果:
1 | Predicate<Apple> redAndHeavyAppleOrGreen = |
请注意,and和or方法是按照在表达式链中的位置,从左向右确定优先级的。因此,a.or(b).and(c)可以看作(a || b) && c。
函数复合
Function接口为此配了andThen和compose两个默认方法,它们都会返回Function的一个实例。
andThen方法,会返回一个函数,它先对输入应用一个给定函数,再对输出应用另一个函数。
1 | Function<Integer, Integer> f = x -> x + 1; //数学上会写作g(f(x)) |
compose方法,先把给定的函数用作compose的参数里面给的那个函数,然后再把函数本身用于结果。
1 | Function<Integer, Integer> f = x -> x + 1; //数学上会写作f(g(x)) |
流与集合
只能遍历一次
流和迭代器类似,只能遍历一次。遍历完后,这个流已经被消费掉了。
可以从原始数据源那里再获得一个新的流来重新遍历一遍,就像迭代器一样(这里假设它是集
合之类的可重复的源,如果是I/O通道就没戏了)。
外部迭代与内部迭代
使用Collection接口需要用户去做迭代(比如用for-each),这称为外部迭代。 相反, Streams库使用内部迭代,它帮你把迭代做了,还把得到的流值存在了某个地方,你只要给出一个函数说要干什么就可以了。
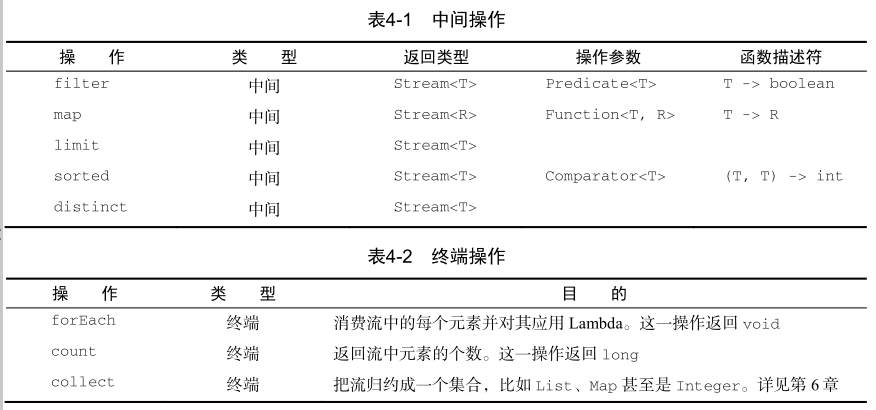
流操作
可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作。
1)中间操作:一般都可以合并起来,在终端操作时一次性全部处理。
2)终端操作:会从流的流水线生成结果。其结果是任何不是流的值,比如List、Integer,甚
至void。
使用流
基本的一些流操作:filter筛选,distinct去重,limit截断,skip跳过
映射
1)对流中每一个元素应用函数:流支持map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一 个新版本“,而不是去“修改”)。
1 | List<String> dishname = list.stream().map(Dish::getName).collect(Collectors.toList()); |
2)流的扁平化
flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。flatmap方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接起来成为一个流。
1 | Stream<int[]> stream = list1.stream() //使用flatMap |
归约
即把集合中的元素反复结合起来,得到一个值,即将流归约为一个值,用函数式编程语言叫折叠。
1)元素求和:reduce方法
reduce接受两个参数:
- 一个初始值,这里是0;
- 一个BinaryOperator<T>来将两个元素结合起来产生一个新值。
在Java 8中,Integer类现在有了一个静态的sum方法来对两个数求和,这恰好是我们想要的,用不着反复用Lambda写同一段代码了:
1 | int sum = numbers.stream().reduce(0, Integer::sum); |
无初始值
reduce还有一个重载的变体,它不接受初始值,但是会返回一个Optional对象:
1 | Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b)); |
为什么它返回一个Optional<Integer>呢?考虑流中没有任何元素的情况。reduce操作无法返回其和,因为它没有初始值。这就是为什么结果被包裹在一个Optional对象里,以表明和可能不存在。
map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名,因为它很容易并行化。
流操作:无状态和有状态
map或filter等操作会从输入流中获取每一个元素,并在输出流中得到0或1个结果。这些操作一般都是无状态无状态的:它们没有内部状态(假设用户提供的Lambda或方法引用没有内部可变状态)。
reduce、sum、max等操作需要内部状态来累积结果。在上面的情况下,内部状态很小。在我们的例子里就是一个int或double。不管流中有多少元素要处理,内部状态都是有界的。
sort或distinct等操作一开始都和filter和map差不多——都是接受一个流,再生成一个流(中间操作),但有一个关键的区别。从流中排序和删除重复项时都需要知道先前的历史。例如,排序要求所有元素都放入缓冲区后才能给输出流加入一个项目,这一操作的存储要求是无界的。要是流比较大或是无限的,就可能会有问题(把质数流倒序会做什么呢?它应当返回最大的质数,但数学告诉我们它不存在)。我们把这些操作叫作有状态操作。
数值流
我们在前面看到了可以使用reduce方法计算流中元素的总和。例如,你可以像下面这样计算菜单的热量:
1 | int calories = menu.stream() |
这段代码的问题是,它有一个暗含的装箱成本。每个Integer都必须拆箱成一个原始类型,再进行求和。但 Stream API还提供了原始类型流特化,专门支持处理数值流的方法。
原始类型流特化
Java 8引入了三个原始类型特化流接口来解决这个问题:IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double,从而避免了暗含的装箱成本。每个接口都带来了进行常用数值归约的新方法,比如对数值流求和的sum,找到最大元素的max。此外还有在必要时再把它们转换回对象流的方法。
- 映射到数值流
将流转换为特化版本的常用方法是mapToInt、mapToDouble和mapToLong。这些方法和前面说的map方法的工作方式一样,只是它们返回的是一个特化流,而不是Stream<T>。
1 | int calories = menu.stream() |
这里,mapToInt会从每道菜中提取热量(用一个Integer表示),并返回一个IntStream(而不是一个Stream<Integer>)。如果流是空的,sum默认返回0。IntStream还支持其他的方便方法,如max、min、average等。
转换回对象流
由于IntStream的map操作接受的Lambda必须接受int并返回int,那有时可能会想把数值流转换回非特化流。
要把原始流转换成一般流(每个int都会装箱成一个Integer),可以使用boxed方法。
1
2IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
Stream<Integer> stream = intStream.boxed();
数值范围&生成数
Java 8引入了两个可以用于IntStream和LongStream的静态方法,帮助生成这种范围:range和rangeClosed。这两个方法都是第一个参数接受起始值,第二个参数接受结束值。但range是不包含结束值的:[l, r),而rangeClosed则包含结束值:[l, r]。
1 | IntStream evenNumbers = IntStream.rangeClosed(1, 100) //表示范围[1, 100] |
构建流
由值创建流
使用静态方法Stream.of,通过显式值创建一个流。
1
2
3Stream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action");
stream.map(String::toUpperCase).forEach(System.out::println);
Stream<String> emptyStream = Stream.empty();//空流由数组创建流
Arrays.stream从数组创建一个流。
1
2int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();由文件生成流
Java中用于处理文件等I/O操作的NIO API(非阻塞 I/O)已更新,以便利用Stream API。java.nio.file.Files中的很多静态方法都会返回一个流。比如:
Files.lines,它会返回一个由指定文件中的各行构成的字符串流。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Pattern pattern = Pattern.compile("[a-zA-Z]+"); //统计一个英文文件中各个单词出现的次数,并排序
try (Stream<String> lines = Files.lines(Paths.get("D:/data.txt"), Charset.defaultCharset())) {
final Map<String, Long> collect = lines.flatMap(i -> {
final String[] s1 = i.split(" ");
for (int j = 0; j < s1.length; j++) {
final Matcher matcher = pattern.matcher(s1[j]);
s1[j] = matcher.find() ? matcher.group() : "";
}
return Arrays.stream(s1);
}).collect(Collectors.groupingBy(i -> i, Collectors.counting()));
final ArrayList<Map.Entry<String, Long>> entries = new ArrayList<>(collect.entrySet());
entries.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));
System.out.println(entries);
System.out.println(entries.stream().mapToLong(Map.Entry::getValue).sum());
} catch (IOException ignore) { }由函数生成流:创建无限流
Stream API提供了两个静态方法来从函数生成流:Stream.iterate和Stream.generate。 这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由iterate 和generate产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去!必须使用limit(n)来对这种流加以限制。
1
2IntStream.iterate(0, a -> a + 2).limit(10).forEach(System.out::println);
IntStream.generate(() -> 1).limit(10).forEach(System.out::println);iterate方法接受一个初始值(在这里是0),还有一个依次应用在每个产生的新值上的Lambda(UnaryOperator<t>类型)。
generate接受一个Supplier<T>类型的Lambda提供新的值。
用流收集数据
归约和汇总
maxBy/minBy:计算流中的最大或最小值。
summingInt/summingLong/summingDouble:生成一个用于求元素和的Collector,首先通过给定的mapper将元素转换类型,然后再求和。参数的作用就是将元素转换为指定的类型,最后结果与转换后类型一致。
1 | int i = list.stream().limit(3).collect(Collectors.summingInt(Integer::valueOf));//list中String转为int求和 |
averagingInt/averagingLong/averagingDouble:生成一个用于求元素平均值的Collector,首选通过参数将元素转换为指定的类型。用法和上面差不多。
joining:joining工厂方法返回的收集器会把对流中每一个对象应用toString方法得到的所有字符串连接成一个字符串。在内部使用了StringBuilder来把生成的字符串逐个追加起来。可以指定连接符,甚至是结果的前后缀。
1 | String shortMenu = menu.stream().map(Dish::getName).collect(joining()); |
reducing
我们已经讨论的所有收集器,都是一个可以用reducing工厂方法定义的归约过程的特殊情况而已。Collectors.reducing工厂方法是所有这些特殊情况的一般化。可以说,先前讨论的案例仅仅是为了方便程序员而已。
它需要三个参数。
- 第一个参数是归约操作的起始值,也是流中没有元素时的返回值,所以很显然对于数值和而言0是一个合适的值。
- 第二个参数就是应用于每个输入值的映射函数。
- 第三个参数是一个BinaryOperator,将两个项目累积成一个同类型的值。这里它就是对两个int求和。
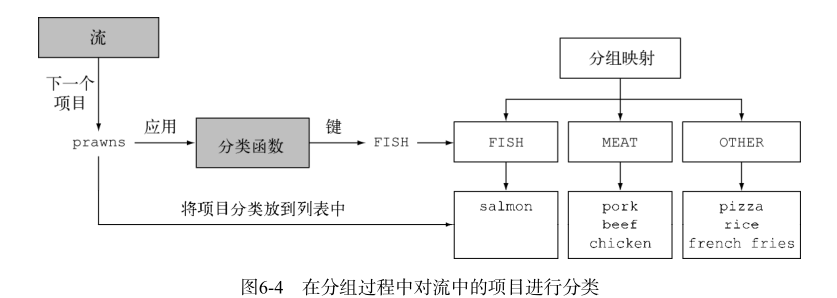
分组
给groupingBy方法传递了一个Function(以方法引用的形式),它提取了流中每 一道Dish的Dish.Type。
我们把这个Function叫作分类函数,因为它用来把流中的元素分成不同的组。
分组操作的结果是一个Map,把分组函数返回的值作为映射的键,把流中所有具有这个分类值的项目的列表作为对应的映射值。
1 | Map<Integer, List<String>> collect = lists.stream().collect(Collectors.groupingBy(String::length)); |
多级分组
要实现多级分组,我们可以使用一个由双参数版本的Collectors.groupingBy工厂方法创建的收集器,它除了普通的分类函数之外,还可以接受collector类型的第二个参数。那么要进行二级分组的话,我们可以把一个内层groupingBy传递给外层groupingBy,并定义一个为流
中项目分类的二级标准。
1 | lists.stream().collect(Collectors.groupingBy(String::hashCode, Collectors.groupingBy(String::length))); |
按子组收集数据
groupingBy的第二个参数可以是Collector,所以除了多级分组还有别的用处。
比如查询某种菜的数量:
1 | Map<Dish.Type, Long> typesCount = menu.stream().collect(groupingBy(Dish::getType, counting())); |
把收集器的结果转换为另一种类型
1 | Map<Dish.Type, Dish> mostCaloricByType = Dish.menu.stream() |
分区
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,于是它最多可以分为两组——true是一组,false是一组。
1 | Map<Boolean, List<Dish>> partitionedMenu = |
用Optinal取代null
变量存在时,Optional类只是对类简单封装。变量不存在时,缺失的值会被建模成一个“空” 的Optional对象,由方法Optional.empty()返回。Optional.empty()方法是一个静态工厂 方法,它返回Optional类的特定单一实例。:如果你尝试引用一个null,一定会触发NullPointerException,不过使用Optional.empty()就完全没事儿,它是Optional类的一个有效对象,多种场景都能调用,非 常有用。
创建Optional对象
声明一个空的Optional ,可以通过静态工厂方法Optional.empty,创建一个空的Optional 对象:
1
Optional<Car> optCar = Optional.empty();
依据一个非空值创建Optional :还可以使用静态工厂方法Optional.of,依据一个非空值创建一个Optional对象:
1
Optional<Car> optCar = Optional.of(car);
可接受null的Optional ,使用静态工厂方法Optional.ofNullable,你可以创建一个允许null值的Optional 对象:
1
Optional<Car> optCar = Optional.ofNullable(car);
使用map 从 Optional 对象中提取和转换值
1
2Optional<Insurance> optInsurance = Optional.ofNullable(insurance);
Optional<String> name = optInsurance.map(Insurance::getName);默认行为即解引用的Optional对象
get()是这些方法中最简单但又最不安全的方法。如果变量存在,它直接返回封装的变量 值,否则就抛出一个NoSuchElementException异常。所以,除非你非常确定Optional 变量一定包含值,否则使用这个方法是个相当糟糕的主意。此外,这种方式即便相对于 嵌套式的null检查,也并未体现出多大的改进。orElse(T other)它允许你在 Optional对象不包含值时提供一个默认值。orElseGet(Supplier<? extends T> other)是orElse方法的延迟调用版,Supplier 方法只有在Optional对象不含值时才执行调用。如果创建默认值是件耗时费力的工作, 你应该考虑采用这种方式(借此提升程序的性能),或者你需要非常确定某个方法仅在 Optional为空时才进行调用,也可以考虑该方式(这种情况有严格的限制条件)。orElseThrow(Supplier<? extends X> exceptionSupplier)和get方法非常类似, 它们遭遇Optional对象为空时都会抛出一个异常,但是使用orElseThrow你可以定制希 望抛出的异常类型。ifPresent(Consumer<? super T>)让你能在变量值存在时执行一个作为参数传入的 方法,否则就不进行任何操作。
新的日期和时间API
LocalDate、LocalTime、Instant、Duration 以及 Period
LocalDate、LocalTime
通过静态工厂方法of创建一个实例。
1 | LocalDate localDate = LocalDate.of(2021, 3, 16); |
机器的日期和时间格式:Instant
你可以通过向静态工厂方法ofEpochSecond传递一个代表秒数的值创建一个该类的实例。
Instant类也支持静态工厂方法now,它能够帮你获取当前时刻的时间戳
1 | Instant.ofEpochSecond(12, 32);//从UNIX元年1970年1月1日,往后12秒,再加上32纳秒,第二个参数可以是负数,意思是减去 |
定义 Duration 或 Period
Duration类的静态工厂方法between就是为求两个时间中间差而设计的。可以创建两个LocalTimes对象、两个LocalDateTimes对象,或者两个Instant对象之间的duration。但不能混着创建,比如求LocalDateTimes和Instant对象之间的duration。
1 | Duration d1 = Duration.between(time1, time2); |
但Duration不能求两个LocalDate间的时差,如果你需要以年、月或者日的方式对多个时间单位建模,可以使用Period类。使用该类的工厂方法between,你可以使用得到两个LocalDate之间的时长。
1 | Period tenDays = Period.between(LocalDate.of(2014, 3, 8), LocalDate.of(2014, 3, 18)); |
Duration和Period类都提供了很多非常方便的工厂类,直接创建对应的实例:
1 | Duration threeMinutes = Duration.ofMinutes(3); |
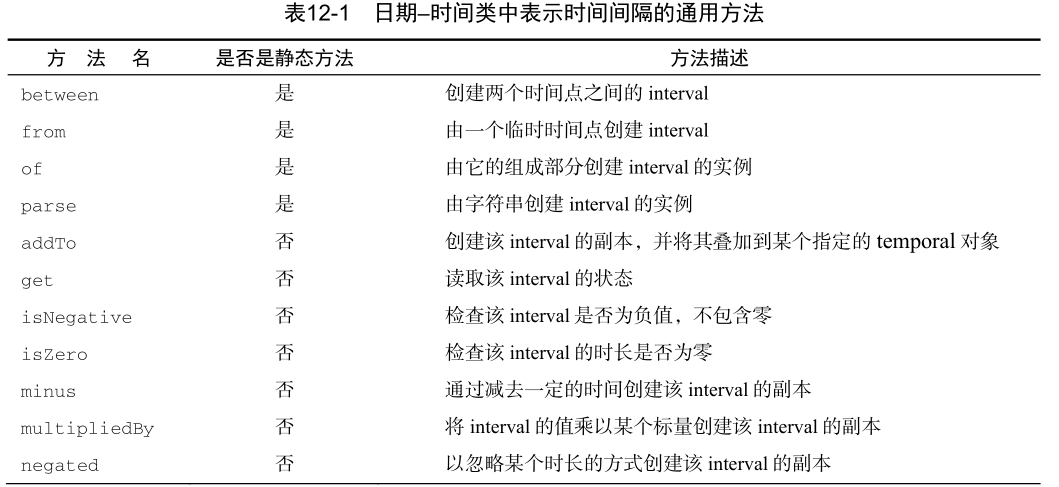

操纵、解析和格式化日期
这些日期对象比如LocalDate以及其内的年月日属性都是final的,也就是说要修改返回的肯定是一个新的对象,保证了线程安全。
1 | LocalDate date1 = LocalDate.of(2014, 3, 18); |
像LocalDate、LocalTime、LocalDateTime以及Instant这样表示时间点的日期时间类提供了大量通用的方法的总结:

使用 TemporalAdjuster
有的时候,你需要进行一些更加复杂的操作,比如,将日期调整到下个周日、下个工作日,或者是本月的最后一天。这时,使用重载版本的with方法,向其传递一个提供了更多定制化选择的TemporalAdjuster对象,更加灵活地处理日期。最常见的用例,日期和时间API已经提供了大量预定义的TemporalAdjuster。可以通过TemporalAdjuster类的静态工厂方法访问它们,如下所示:
1 | LocalDate date1 = LocalDate.of(2014, 3, 18); |

若是没有从表中找到自己需要的方法,那也可以自己定义TemporalAdjuster。
打印输出及解析日期-时间对象
处理日期和时间对象时,格式化以及解析日期-时间对象是另一个非常重要的功能。新的java.time.format包就是特别为这个目的而设计的。这个包中,最重要的类是DateTime- Formatter。创建格式器最简单的方法是通过它的静态工厂方法以及常量。像ASIC_ISO_DATE和ISO_LOCAL_DATE这样的常量是DateTimeFormatter类的预定义实例。所有的DateTimeFormatter实例都能用于以一定的格式创建代表特定日期或时间的字符串。
1 | LocalDate date = LocalDate.of(2014, 3, 18); |
所有的DateTimeFormatter实例都是线程安全的。所以,你能够以单例模式创建格式器实例,就像DateTimeFormatter所定义的那些常量,并能在多个线程间共享这些实例。
1 | DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy"); |

